
La cosa que se me estaba comiendo los viernes
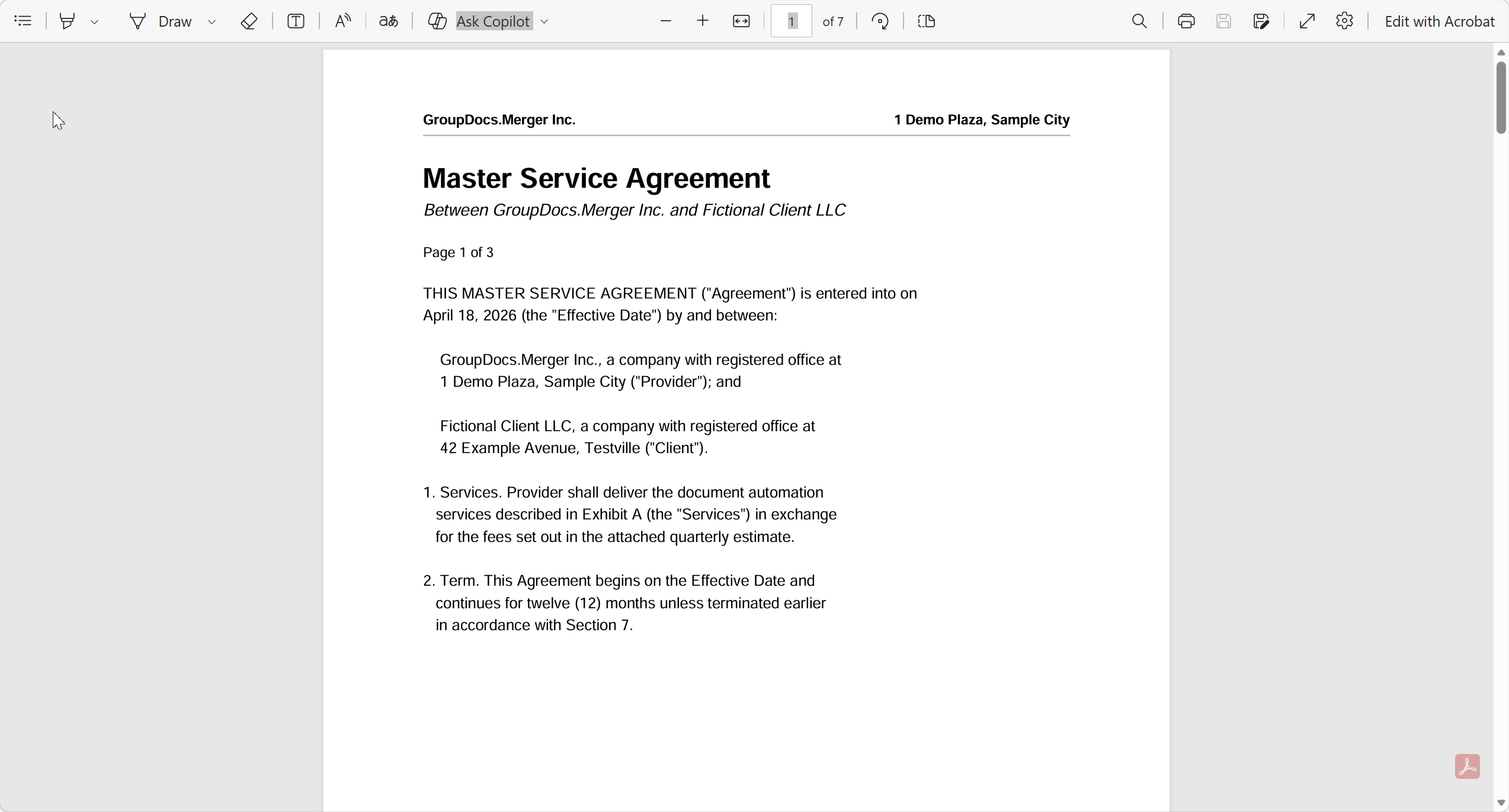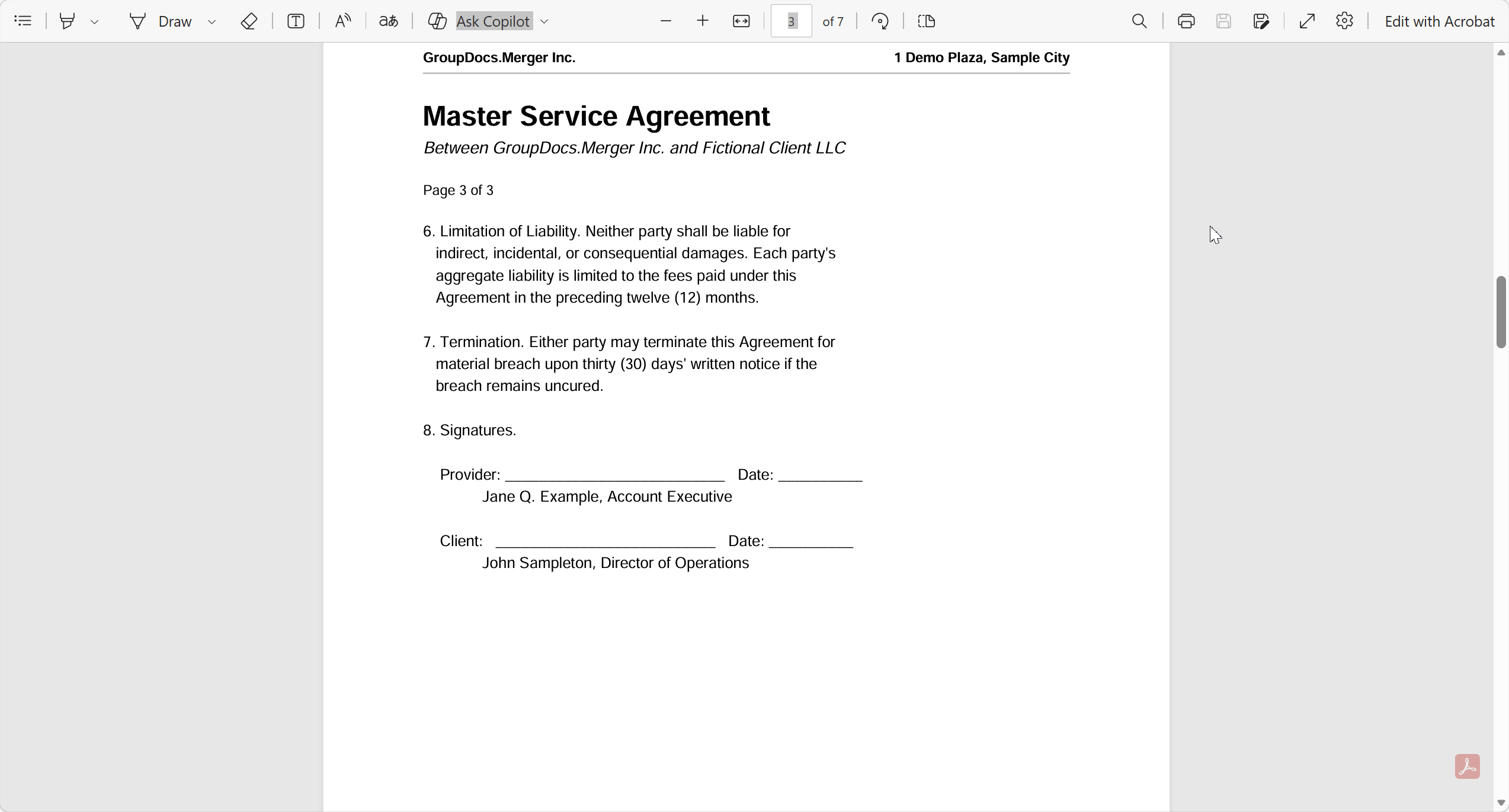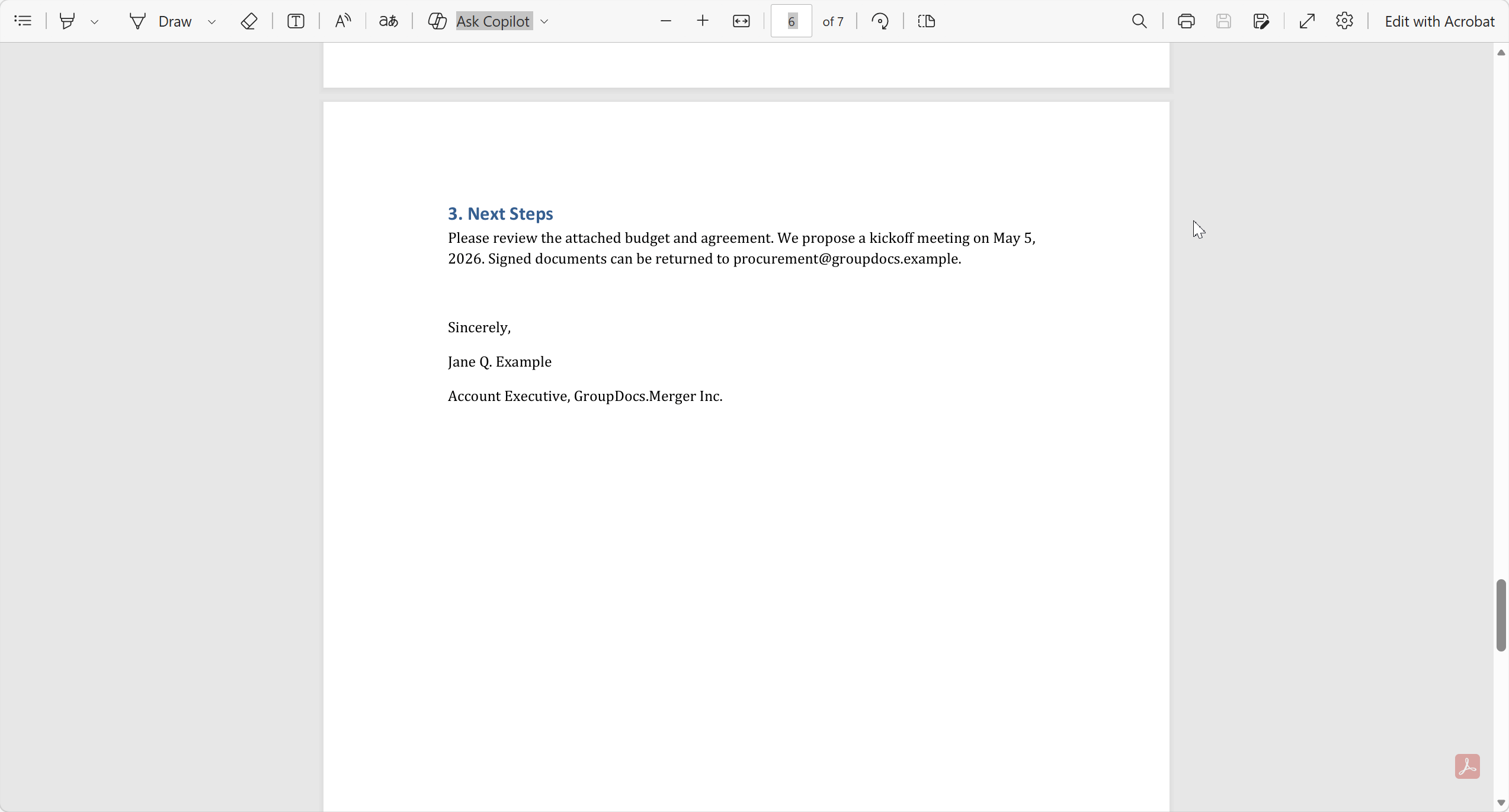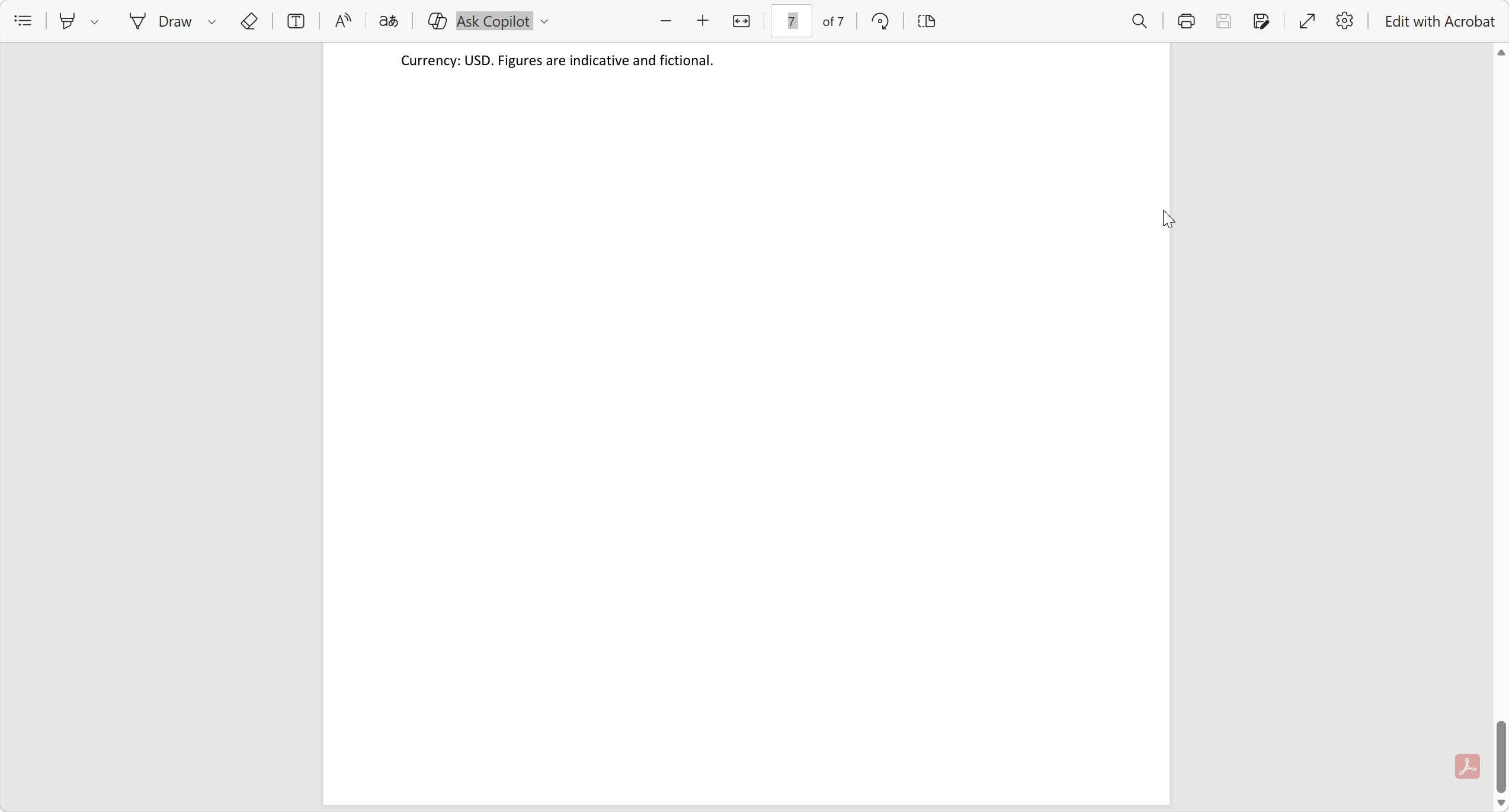
Cada viernes por la tarde, durante aproximadamente un año, tenía el mismo pequeño ritual. Un contrato llegaba como tres archivos — el acuerdo principal en Word, un anexo de precios en Excel y la hoja de términos del socio como PDF — y tenía que entregarlos como un PDF limpio. Nada difícil. Abrir Word, exportar a PDF. Abrir Excel, exportar a PDF. Abrir alguna aplicación gratuita de fusión de PDF, arrastrar los tres archivos, comprobar el orden, guardar.
Tomaba quizá ocho minutos. Multiplica eso por quince contratos a la semana y pierdes dos horas moviendo el ratón. Peor aún, cada pocas semanas alguien enviaba un archivador con el anexo en la primera página porque los nombres de archivo se ordenaban alfabéticamente en la aplicación de fusión.
Si esto te suena familiar, el resto de este artículo es la tarde en que finalmente reemplacé el ritual con código.
El costo real no es el tiempo — es el contrato de cada cincuenta donde las páginas quedan en el orden incorrecto y nadie se da cuenta hasta que el cliente firma la versión equivocada.
Lo que realmente quería
No un “pipeline de documentos elegante”. Sólo tres cosas:
- Pasar a un método una lista de archivos (cualquier combinación de DOCX, XLSX, PDF) y obtener un PDF de vuelta.
- Apuntar la misma lógica a una carpeta y que descubra la lista de archivos por sí misma.
- Extraer un rango de páginas del archivador terminado sin rehacer toda la fusión.
Eso es todo el trabajo. Si la biblioteca no puede hacer esas tres cosas de forma limpia, no quiero saberlo.
Configuración
- .NET 6.0 o posterior
- GroupDocs.Merger for .NET 24.10+ (obtener una licencia temporal para que no se envíe la marca de agua de evaluación)
- Una carpeta con la combinación de documentos que normalmente fusionarías manualmente
dotnet add package GroupDocs.Merger
Eso es todo en cuanto a dependencias. Sin conversor externo, sin instalación de Office sin cabeza, sin biblioteca de manipulación de PDF adicional.
Paso 1 — Dejar que una carpeta sea la entrada
Siempre empiezo aquí porque es el punto de entrada realista. En la práctica, algo más (un manejador de carga, un trabajo de ingestión de correo electrónico, un volcado nocturno de finanzas) deja un montón de archivos en un directorio, y mi código tiene que lidiar con lo que encuentre.
// Pick up every supported file in the drop folder; the PDF wins
// the tie-break for position 0 so the merger keeps the output
// as a PDF regardless of how files are named.
string[] extensions = { ".pdf", ".docx", ".xlsx" };
var files = Directory.EnumerateFiles(folderPath)
.Where(f => extensions.Contains(Path.GetExtension(f).ToLowerInvariant()))
.OrderBy(f => Path.GetExtension(f).ToLowerInvariant() == ".pdf" ? 0 : 1)
.ThenBy(f => f)
.ToArray();
if (files.Length == 0)
throw new InvalidOperationException(
$"No supported documents found in '{folderPath}'.");
El truco del OrderBy es la parte interesante. GroupDocs.Merger elige su formato de salida según el primer archivo que abras; si le paso un DOCX como documento principal, obtengo un DOCX de salida. Como mi pipeline siempre quiere un PDF, me aseguro de que cualquier PDF existente en la carpeta obtenga la posición 0.
Dos cosas que vale la pena mencionar:
ToLowerInvariant()porque algún día un socio te enviaráREPORT.PDFy tu filtro que solo acepta minúsculas lo descartará silenciosamente.- El
ThenBy(f)está solo para que la salida sea determinista. Sin él, dos ejecuciones en la misma carpeta pueden diferir según el estado del sistema de archivos.
Paso 2 — La fusión propiamente dicha
Una vez que tengo una lista ordenada de rutas, la fusión es más corta que la descripción de la fusión.
Console.WriteLine($"Primary source: {sourcePaths[0]}");
using var merger = new Merger(sourcePaths[0]);
var joinOptions = new JoinOptions();
for (int i = 1; i < sourcePaths.Length; i++)
{
Console.WriteLine($"Joining: {sourcePaths[i]}");
merger.Join(sourcePaths[i], joinOptions);
}
merger.Save(outputPath);
Console.WriteLine($"Unified PDF binder saved to: {Path.GetFullPath(outputPath)}");
Algunas notas de usar esto en situaciones reales:
- El
usingimporta.Mergermantiene manejadores de archivo sobre las fuentes; si olvidas disponerlo, el trabajador de la carpeta de entrada eventualmente fallará al intentar eliminar sus propios archivos de entrada. JoinOptionsestá vacío aquí porque los valores predeterminados son lo que quiero el 95 % de las veces. Cuando lo necesites, ahí es donde viven los rangos de páginas, la rotación y las posiciones de inserción.- Cuando Excel entra en el archivador, la disposición hoja‑a‑página la decide el área de impresión del libro de origen. Si tu XLSX termina en 38 páginas y querías tres, la solución está en la hoja de cálculo, no en
JoinOptions.
Una comprobación de sanidad que siempre añado justo después de guardar:
using var verify = new Merger(outputPath);
Console.WriteLine($"Result pages: {verify.GetDocumentInfo().PageCount}");
Dos segundos de código que han atrapado más errores de “anexo descartado silenciosamente” que cualquier prueba que haya escrito.
Paso 3 — Extraer una porción más tarde
La solicitud de seguimiento que recibo cada vez es: “¿Puedes enviarme solo la página de portada?” o “El cliente solo quiere las firmas.” Reconstruir todo el archivador para entregar dos páginas es una tontería — la extracción lo hace directamente.
using var merger = new Merger(binderPath);
merger.ExtractPages(new ExtractOptions(pages));
merger.Save(outputPath);
Console.WriteLine($"Extracted pages [{string.Join(",", pages)}] to " +
Path.GetFullPath(outputPath));
pages es un int[] de números de página basados en 1 que deseas conservar. Todo lo demás se descarta. Es rápido porque el resultado ya es un PDF — sin ida y vuelta de conversión.
Antes vs. después, honestamente
| Lo que solía hacer | Con Merger.Join |
|
|---|---|---|
| Tiempo por contrato | 5–10 minutos de clics | menos de 30 segundos de principio a fin |
| Falla típica | Páginas en el orden incorrecto, nadie lo nota | Cualquier orden que indique la lista de archivos, de forma repetible |
| Escalado a 100/día | No funciona — contratas a una persona | Un trabajador, aburrido la mayor parte del tiempo |
| Código que mantienes | Una página de Confluence titulada “Binder Process v4” | Una clase, ~70 líneas |
| Salida | Tres PDFs y una oración | Un archivador, con recuento de páginas que puedes registrar |
La fila que más me importa es la de “falla”. La fusión manual falla en silencio; el código que registra un recuento de páginas falla en voz alta.
Una historia real de un pequeño equipo legal‑tech
Una startup de dos personas con la que trabajé tenía a una asistente legal cuyo día comenzaba con el ensamblaje de contratos. Acuerdo en Word, precios en Excel, anexo en PDF, todo unido en una app, subido a DocuSign. Aproximadamente ocho minutos por paquete, lo que a 30 paquetes al día era básicamente toda su mañana.
Ellos incorporaron el método de escaneo de carpetas al servicio backend que ya estaba vigilando su correo de entrada. Veinte segundos por paquete, más una línea de registro con el recuento de páginas. La asistente pasó a revisar contratos en lugar de ensamblarlos. Nadie volvió a enviar un archivador desordenado — no porque la biblioteca sea mágica, sino porque la lista de archivos está explícita en el código y puedes compararla.
string folder = @"C:\IncomingContracts";
string output = @"C:\Processed\ContractPackage.pdf";
var files = CreatePdfBinderFromFolder(folder, output);
Console.WriteLine($"Package created: {files}");
Eso es toda la integración. Todo lo anterior (el escuchador de correo, la ruta de almacenamiento) ya estaba listo.
Cosas que no necesité hoy pero que necesitaré mañana
La misma biblioteca hace un montón de cosas que no cubrí porque el artículo se alargaría. Aproximadamente en el orden en que las he usado:
- Watermarks on the output para sellos “DRAFT” en copias previas a la firma.
- Page rotation para escaneos que llegan de lado.
- Custom page ordering cuando el orden de origen no coincide con el orden de entrega.
- PDF encryption para cualquier cosa que vaya a una contraparte externa.
Todo eso está detrás de la misma API Merger. La docs tiene la lista completa — solo quería señalar que “merge” es el iniciador barato y el resto está disponible cuando lo necesites.
Lo que le diría a mi yo del pasado
Si estás a punto de escribir tu propio paso DOCX‑a‑PDF porque “es solo un método”, detente. La conversión es la parte que se deteriora silenciosamente — nuevas funciones de Office, manejo de imágenes escaneadas, fuentes incrustadas, etc. Deja que otra cosa se encargue de esa superficie y dedica tu viernes a algo que no sea ordenar por nombre de archivo.
A dónde ir después:
- Temporary license — necesario para salida sin marca de agua
- Advanced merging options — JoinOptions, opciones de guardado, compresión
- Supported formats — mucho más allá de los tres que mostré aquí
- Sample projects on GitHub — incluido este