
Make your corporate documents AI-ready — reliably, on-premise, and semantically.
It is quite common case when organizations keep their documentation in PDF, DOCX, XLSX and ePub formats. While LLMs (large language models) work well with HTML or plain text, these native document formats need conversion before they can be used effectively in LLM + RAG pipelines where we want to chat with a document or a set of documents.
LLM (Large Language Model) — a pre-trained AI model that generates text and answers based on large text corpora.
RAG (Retrieval-Augmented Generation) — an approach that combines an LLM with an external knowledge base (for example, corporate documents) so the model can retrieve and reason over domain content.
The following sequence diagram illustrates the typical steps involved in generating an answer to a question:
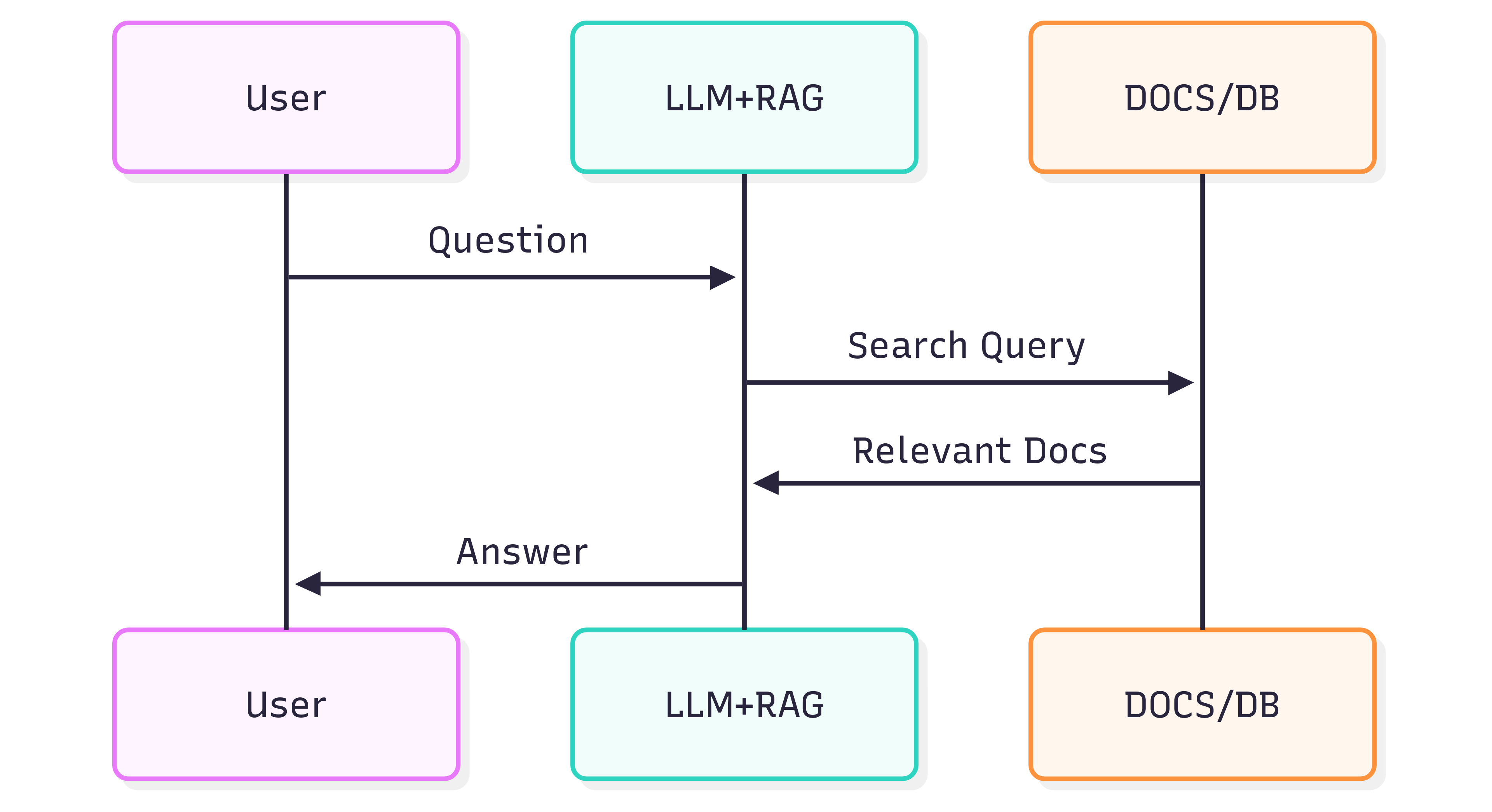
The quality of answers you get from a System (LLM + RAG) depends both on the System itself and on how well the source documents preserve their structure and meaning when fed into the retrieval pipeline.
The problem
Document formatting is not only visual — it carries semantics. Headings, lists, tables, bold/italic emphasis, captions, and inline images all convey meaning that helps an LLM understand context. Naïvely converting documents (for example, using OCR that treats every page as a flat image) often loses those semantics. As a result, RAG retrieval and downstream LLM answers can become inaccurate or noisy.
OCR can help for scanned documents but frequently removes structure (lists split across pages, table borders misinterpreted, lost annotations). It also adds cost and infrastructure overhead when processing large archives.
The solution
An alternative approach is to parse documents with structural awareness and export that structure to a semantic, LLM-friendly format — Markdown. Markdown is lightweight, widely supported, and preserves headings, lists, tables, code blocks, emphasis, captions, and image references — exactly the features that improve retrieval quality.
GroupDocs.Markdown for .NET converts popular document formats (PDF, DOCX, XLSX, ePub, and more) into clean, semantic Markdown suitable for ingestion into RAG systems. It’s an on-premise .NET library, so all processing happens inside your environment — no external services, no data leakage, and no dependency on remote GPUs.
How to get started
GroupDocs.Markdown for .NET is available as a NuGet package, and also as MSI and ZIP downloads.
Install the NuGet package with the .NET CLI:
dotnet add package GroupDocs.Markdown
Or download installers and assemblies from the official downloads page: https://releases.groupdocs.com/markdown/net/
Example usage (add to Program.cs):
// Import the namespace
using GroupDocs.Markdown;
// Set the license (optional for evaluation)
License.Set("GroupDocs.Markdown.lic");
// Instantiate the converter for a source document
var converter = new MarkdownConverter("rich-text-formatting.docx");
// Convert and save output to file
converter.Convert("rich-text-formatting.md");
The converted rich-text-formatting.md file will be saved in the same folder as your application.
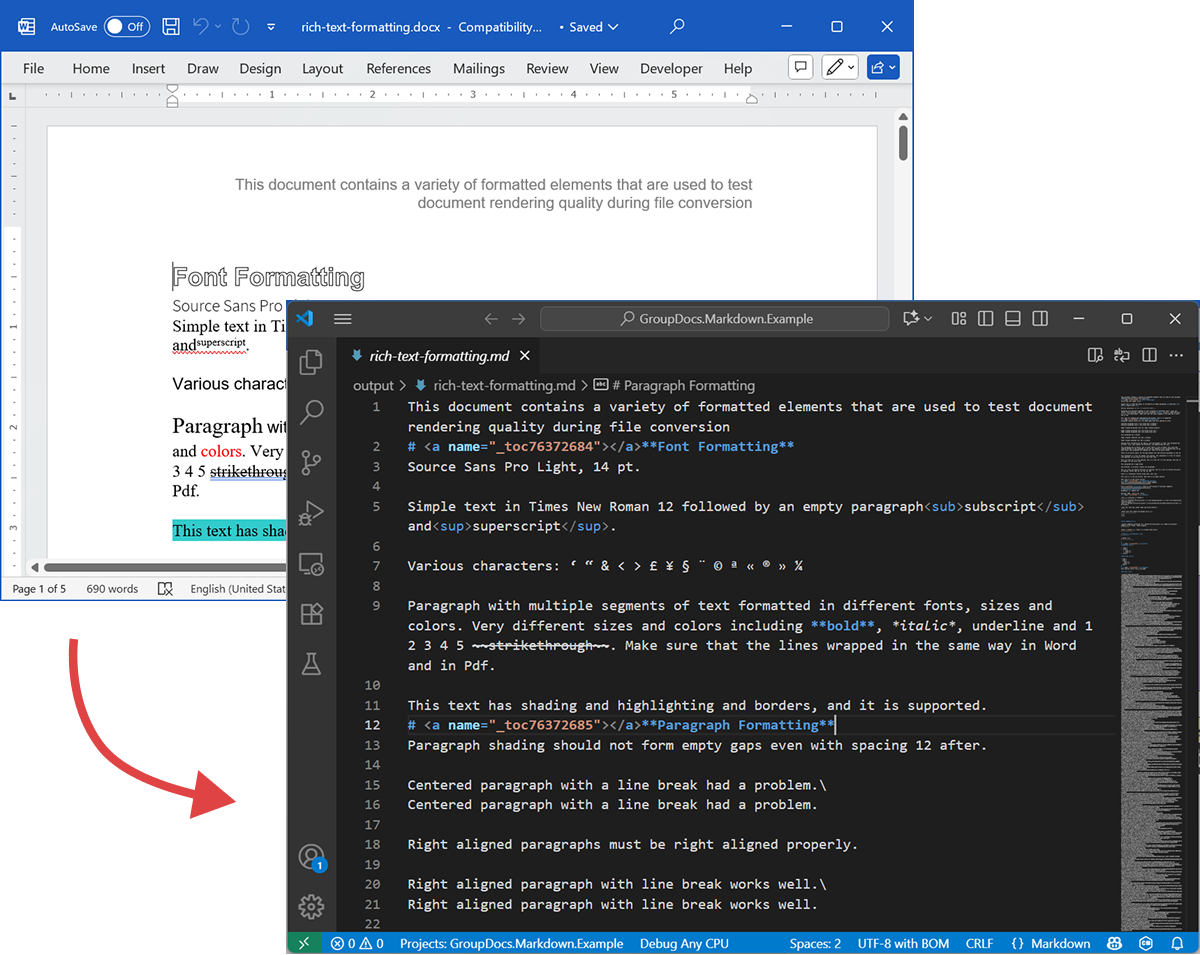
The following screenshot shows input DOCX file and output Markdown.
If you run without a license, the evaluation mode will process a limited number of pages (for example, the first three pages). To try the full product, request a temporary license.
To request a temporary license, open the Purchase Wizard, provide contact details, and click Get a temporary license on the Contact Details step. The temporary license will be emailed to you.
Learn more about temporary licenses: https://purchase.groupdocs.com/temporary-license/.
Supported file formats
GroupDocs.Markdown for .NET supports a broad set of common enterprise and ebook formats. The full list of supported extensions:
- PDF
pdf
- Spreadsheets
.xls,.xlsx,.xlsb,.xlsm,.xlt,.xltx,.xltm,.xlam,.csv,.tsv,.ods,.ots,.fods,.numbers,.sxc
- Word / Rich Text
.doc,.docx,.dot,.dotm,.dotx,.docm,.rtf,.odt,.ott
- Ebooks
.azw3,.mobi,.epub
- Text / Markup / Help
.chm,.xml,.txt
How it works (internals — high level)
When a document is processed, two main phases occur:
-
Document model extraction
The document is parsed into an in-memory object model that represents structural elements (paragraphs, headings, lists, tables, images, footnotes, annotations, etc.). The parser strives to preserve semantics (for example, list nesting, table cells, and image captions). -
Markdown generation
The object model is walked and converted to Markdown according to configurable conversion options (how to handle images, table formatting, heading levels, special annotations, etc.). The result is a readable, semantically meaningful Markdown file ready for indexing by your RAG pipeline.
Export Example
The code example above shows how to export DOCX to Markdown. Lets take this code example and take a look at the source and output files as a demonstration.
Source DOCX
The source file rich-text-formatting.docx contains various content blocks and is heavily formatted to highlight the main semantic elements.
Output Markdown
The output content of rich-text-formatting.md is provided below, showing how different formatting elements are represented in the generated Markdown file.
This document contains a variety of formatted elements that are used to test document rendering quality during file conversion
# <a name="_toc76372684"></a>**Font Formatting**
Source Sans Pro Light, 14 pt.
Simple text in Times New Roman 12 followed by an empty paragraph<sub>subscript</sub> and<sup>superscript</sup>.
Various characters: ‘ “ & < > £ ¥ § ¨ © ª « ® » ¼
Paragraph with multiple segments of text formatted in different fonts, sizes and colors. Very different sizes and colors including **bold**, *italic*, underline and 1 2 3 4 5 ~~strikethrough~~. Make sure that the lines wrapped in the same way in Word and in Pdf.
This text has shading and highlighting and borders, and it is supported.
# <a name="_toc76372685"></a>**Paragraph Formatting**
Paragraph shading should not form empty gaps even with spacing 12 after.
Centered paragraph with a line break had a problem.\
Centered paragraph with a line break had a problem.
Right aligned paragraphs must be right aligned properly.
Right aligned paragraph with line break works well.\
Right aligned paragraph with line break works well.
This paragraph has a border.
Right aligned condensed text had a problem.
Right aligned expanded text had a problem.
Spacing after and before do not add up, just the greater is used. This paragraph has 12 after. Also, when indents are different, the shading does not join.
This paragraph has 12 before, but in total there is only 12 above. Also note that shading belongs to the paragraph at the top and shading of this paragraph does not go down unless next paragraph has shading too. There are 24 points below.
There are 24 points above, but the gap between this and previous paragraph is only 24.
This paragraph is a test for double line spacing. This paragraph is a test for double line spacing. It also have 0.5” for the first line.
This is a test for 1.5 line spacing. This is a test for 1.5 line spacing. Also has -0.5” indent for the first line.
This paragraph has a page break
and centered. It actually creates two paragraphs.
This is a test for Exactly 20 points of spacing. This is a test for Exactly 20 points of spacing. TTTTTT (20, 22, 24, 26, 28, 30).
There is a continuous section break after this line.
This line is in the new section. Next here is an empty section.
This line is in the fourth section.
# <a name="_toc76372686"></a>**Paragraph Justify**
This is a justified paragraph with a single segment. 111111111111111111111111111111111111111111.
Also a justified **paragraph** reset to left because of multiple segments. 111111111111111111111111111111111111111111.
# **Non-English Characters**
Wingdings: (x, Symbol: WÄ
Russian: Теперь немного по русски.
# <a name="_toc76372687"></a>**Tables**
|Cell 1.1 Left|Cell 1.2 Right|||
| :- | -: | :- | :- |
|Cell 2.1 Centered vertically|Cell 2.2 with background|Cell 2.3 with line break<br>and coloured border.||
|Cell 3.1 Bottom vertically|<p>Cell 3.2</p><p>Centered</p><p>Horizontally</p>|Cell 3.3 No border||
|Left red, blue top, green right and yellow bottom.|
| :- |
|Table with left indent and merged cells.||||
| :- | :- | :- | :- |
|||||
|||||
**Cell padding etc.**
|<p>Cell padding.</p><p>Top: 0.1, bottom 0.2</p><p>Left: 0.5, Right 0.4</p>|Zero padding on all sides, right aligned.|
| :- | -: |
|Outer 1.1|Outer 1.2. There is a nested table here||
| :- | :-: | -: |
|**Nested 1.1**|**Nested 1.2**|
| :- | :- |
|||Outer 1.3|
| :- | :-: | -: |
#
# <a name="_toc76372688"></a>**Lists**
**Numbered list:**
1. Item 1
1. Item 2
1. Item 2.1
1. Item 2.2
1. Item 3
**Bulleted list:**
- Item 1
- Item 2
- Item 2.1
- Item 2.2
- Item 3
#
# <a name="_toc76372689"></a>**Images**
This section starts from a new page.
**Ellipse text**
There is an image in a black border in the top right corner, but it will drop down into the text. There is also a transparent ellipse with text that overlaps the picture.
Inline JPEG in a separate paragraph.

Inline GIF scaled 50% and WMF scaled 25% in a paragraph. This text is before the image and  this text is after the image.
Images in a table. Left and right aligned.
|||
| :- | -: |
Inline text box  is here and inline ellipse  is here.
New section that starts from a new page is here.
It has portrait orientation and margins.
# <a name="_toc76372690"></a>**Fields**
Merge field «FirstName»
Page number 5
Hyperlink [Aspose.com](http://www.aspose.com)
TOC
[Font Formatting 1](#_toc76372684)
[Paragraph Formatting 1](#_toc76372685)
[Non-English Characters 2](#_toc76372686)
[Tables 2](#_toc76372687)
[Lists 2](#_toc76372688)
[Images 4](#_toc76372689)
[Fields 5](#_toc76372690)
# **Form Fields**
Edit <a name="text1"></a>test text
Checkbox <a name="check1"></a>
Combobox <a name="dropdown1"></a>
# **Footnotes and Endnotes**
This line has a footnote at the end.[^1]
This line has an endnote at the end.[^2]
[^1]: Footnote 1.
[^2]: Endnote 1.
Summary
GroupDocs.Markdown for .NET helps you convert a wide range of document formats into semantic Markdown that is ready for LLM + RAG systems. It preserves document structure and meaning, runs on-premise, and supports common enterprise formats — making it a practical choice for organizations that need to prepare large document collections for AI consumption.
Learn more
- Product home: https://products.groupdocs.com/markdown/net/
- Documentation: https://docs.groupdocs.com/markdown/net/
- License information: https://about.groupdocs.com/legal/
- Downloads: https://releases.groupdocs.com/markdown/net/
Support & feedback
For questions or technical assistance, please use our Free Support Forum — we’ll be happy to help.